

图片来源:Pixabay
2016年 ,“阿尔法狗(AlphaGo)”与李世石的围棋对决,让人工智能和深度学习进入了大众的视野。在那场人机大战中,阿尔法狗以总分4比1获胜。不仅围棋,深度学习近些年迅猛发展,在语言、医疗等多种领域展现出了强大的能力。然而这一切是有代价的,为了降低错误率,深度学习在完成任务时需要越来越大的计算量,由此产生的经济成本、耗费的电量、对环境的污染,将超出人类社会的承受能力。人工智能普及的那一天,或许也将是人类能源被计算机消耗殆尽的那一天?
编译 | 郑昱虹
审校 | 白德凡
当下风头正劲的深度学习领域,起源于真空管计算机的时代。1958年,康奈尔大学的弗兰克·罗森布拉特(Frank Rosenblatt) 受大脑神经元的启发,设计了第一个人工神经网络,之后被命名为“深度学习”。罗森布拉特知道,这项技术超越了当时的计算能力,他惋惜地表示:“随着神经网络连接节点的增加……传统的数字计算机很快就会无法承担计算量的负荷。”
幸运的是,计算机硬件在几十年间快速升级,使计算速度提高了大约1000万倍。因此,21世纪的研究人员得以实现具有更多连接的神经网络,用来模拟更复杂的现象。如今深度学习已经广泛普及,被应用于下围棋、翻译、预测蛋白质折叠、分析医学影像等多种领域。
深度学习的崛起势如破竹,但它的未来很可能是坎坷的。罗森布拉特所担忧的计算量的限制,仍然是笼罩在深度学习领域之上的一片阴云。如今,深度学习领域的研究人员正在逼近计算工具的极限。
深度学习的工作原理
深度学习是人工智能领域长期发展的成果。早期的人工智能系统基于逻辑和人类专家给定的规则,之后渐渐引入了可以通过学习来调节的参数。而今,神经网络可以通过学习,构建可塑性很强的计算机模型。神经网络的输出不再是单一公式的结果,而是采用了极其复杂的运算。足够大的神经网络模型可以适应任何类型的数据。
为了理解“专家系统(expert-system approach)”和“灵活系统(flexible-system approach)”的区别,我们考虑这样一个场景:通过X光片判断病人是否患有癌症。我们假设X光片中有100个特征(变量),但我们不知道哪些特征是重要的。
专家系统解决问题的方法,是让放射学和肿瘤学领域的专家指定重要的变量,并允许系统只检查这些变量。这一方法需要的计算量小,因此曾被广泛采用。但如果专家没能指出关键的变量,系统的学习能力就不如人意。
而灵活系统解决问题的方法,是检查尽可能多的变量,并由系统自行判断哪些重要。这需要更多的数据和更高的计算成本,相比专家系统效率更低。但是,只要有足够的数据和计算量,灵活系统可以比专家系统表现更优。
深度学习模型是过参数化的(overparameterized),即参数比可供训练的数据点多。比如图像识别系统Noisy Student的神经网络拥有4.8亿个参数,但它在训练时只使用了120万个标记的图像。过参数化通常会导致过拟合(overfitting),也就是模型与训练的数据集拟合度过高,以至于没有把握一般趋势,却学习了训练集的特殊性。深度学习通过随机初始化参数、 “随机梯度下降(stochastic gradient descent)” 等方法,反复调整参数集,以避免过拟合的问题。
深度学习已经在机器翻译领域大显身手。早期,翻译软件根据语法专家制定的规则进行翻译。在翻译乌尔都语、阿拉伯语、马来语等语言时,基于规则的方法起先优于基于统计学的深度学习方法。但是随着文本数据的增加,深度学习全面超越了其他方法。事实证明,深度学习在几乎所有应用领域都具有优越性。
巨大的计算成本
一个适用于所有统计学模型的规则是:要想使性能提高k倍,至少需要k2倍的数据来训练模型。又因为深度学习模型的过参数化,使性能提高k倍将需要至少k4倍的计算量。指数中的“4”意味着,增加10 000倍计算量最多能带来10倍的改进。
显然,为了提高深度学习模型的性能,科学家需要构建更大的模型,使用更多的数据训练。但是计算成本会变得多昂贵呢?是否会高到我们无法负担,并因此阻碍该领域的发展?
为了探究这一问题,麻省理工学院的科学家收集了1000余篇深度学习研究论文的数据,涉及图像分类、目标检测、问答系统、命名实体识别和机器翻译等领域。他们的研究警告,深度学习正面临严峻的挑战。“如果不能在不增加计算负担的前提下提高性能,计算量的限制就会使深度学习领域停滞不前。”
以图像分类为例。减少图像分类错误伴随着巨大的计算负担。例如,2012年 AlexNet模型首次展示了在图形处理器(GPU)上训练深度学习系统的能力,该模型使用两个GPU进行了5 ~ 6天的训练。到2018年,另一个模型NASNet-A的错误率降低到了AlexNet的一半,但它使用的计算量是AlexNet的1000多倍。
芯片性能的提升是否跟上了深度学习的发展?并没有。在NASNet-A增加的1000多倍的计算量中,只有6倍的提升来自于更好的硬件,其余都是通过使用更多的处理器或运行更长时间达到的,伴随着更高的成本。
理论告诉我们, 提高k倍的性能需要增加k4倍的计算量,但在实践中,增加的计算量至少是k4倍。这意味着,要想将错误率减半,需要500倍以上的计算资源,成本高昂。不过,实际情况与理论预测的差距,也意味着可能存在改进算法的空间,有机会提高深度学习的效率。
根据研究人员估计的图像识别领域“计算成本—性能”曲线,将错误率降到5%,需要进行1028次浮点运算。另一项来自马萨诸塞大学阿默斯特分校的研究显示了计算负担隐含的巨大经济和环境成本:训练一个错误率小于5%的图像识别模型,将花费1000亿美元,其消耗的电能产生碳排放与纽约市一个月的碳排放量相当。而想要训练错误率小于1%的图像识别模型,成本就更是天价。
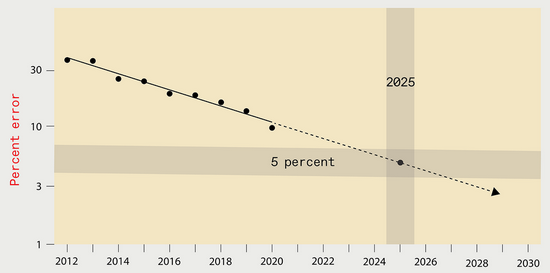
据推断,到2025年,针对ImageNet数据集的最优的图像识别系统,误差率应该降低到5%

但是,训练这样一个深度学习系统将带来相当于纽约市一个月的二氧化碳排放。
(图片来源:N。 C。 Thompson, K。 Greenewald, K。 Lee, G。 F。 Manso)
计算成本的重负在深度学习的前沿已经变得显而易见。机器学习智库OpenAI斥资400多万美元,设计并训练了深度学习语言系统GPT-3。尽管研究人员在操作中犯了一个错误,但他们并没有修复它,仅仅在论文附录中简要解释道:“由于高昂的训练的成本,对模型重新训练是不现实的。”
企业也开始回避深度学习的计算成本。欧洲的一家大型连锁超市最近放弃了一项基于深度学习预测哪些产品将被购买的系统。该公司的高管判断,训练和运行该系统的成本过高。
深度学习路在何方
面对不断上升的经济和环境成本,深度学习领域迫切地需要在计算量可控的前提下,提高性能的方法。研究人员为此进行了大量研究。
一种策略是,使用为深度学习专门设计的处理器。在过去十年中, CPU让位给了GPU、现场可编程门阵列(field-programmable gate arrays)和应用于特定程序的集成电路(application-specific ICs)。这些方法提高了专业化的效率,但牺牲了通用性,面临收益递减。长远看来,我们可能需要全新的硬件框架。
另一种减少计算负担的策略是,使用更小的神经网络。这种策略降低了每次的使用成本,但通常会增加训练成本。二者如何权衡取决于具体情况。比如广泛应用的模型应当优先考虑巨大的使用成本,而需要不断训练的模型应当优先考虑训练成本。
元学习(meta-learning)有望降低深度学习训练成本。其理念是,让一个系统的学习成果应用于多种领域。例如,与其分别建立识别狗、猫和汽车的系统,不如训练一个识别系统并多次使用。但是研究发现,一旦原始数据与实际应用场景有微小的差异,元学习系统的性能就会严重降低。因此,全面的元学习系统可能需要巨大的数据量支撑。
一些尚未发现或被低估的机器学习类型也可能降低计算量。比如基于专家见解的机器学习系统更为高效,但如果专家不能辨别所有的影响因素,这样的系统就无法与深度学习系统相媲美。仍在发展的神经符号(Neuro-symbolic methods)等技术,有望将人类专家的知识和神经网络的推理能力更好地结合。
正如罗森布拉特在神经网络诞生之初所感受到的困境,今天的深度学习研究者也开始面临计算工具的限制。在经济和环境的双重压力下,如果我们不能改变深度学习的方式,就必须面对这个领域进展缓慢的未来。我们期待一场算法或硬件的突破,让灵活而强大的深度学习模型能继续发展,并为我们所用。
原文链接:
https://spectrum.ieee.org/deep-learning-computational-cost
论文链接:
https://arxiv.org/abs/2007.05558#
参考链接:
https://www.csail.mit.edu/news/computational-limits-deep-learning
本文转自环球科学
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...